Constrained devices
Devices are constrained by CPU, memory, and storage, so cloud-first stacks quickly become too heavy to run where the data starts.
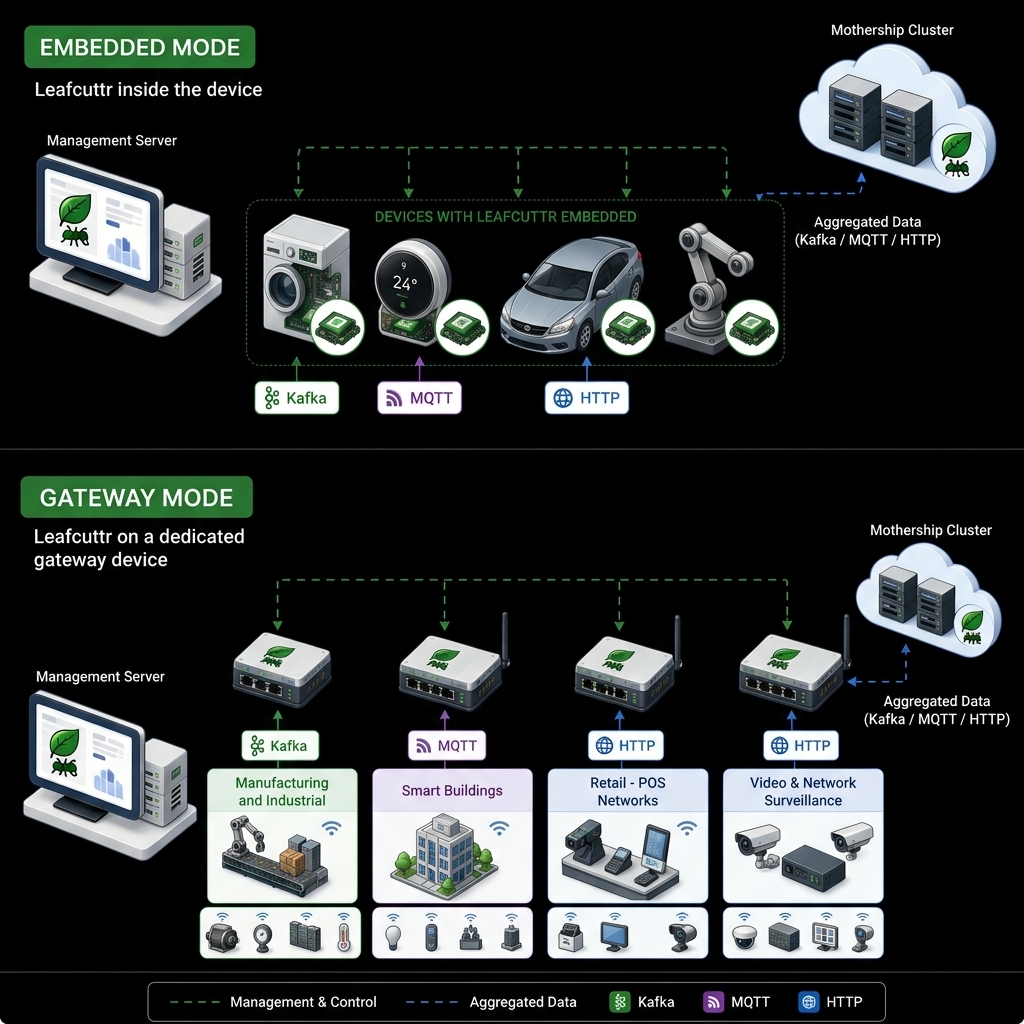
Leafcuttr is a multi-protocol edge gateway built on top of Apache Kafka, with native support for HTTP and MQTT. Designed to run on constrained hardware and flaky networks.
$ docker pull leafcuttr/edge-server:latest
Modern data streaming tools weren’t built for the edge.
Devices are constrained by CPU, memory, and storage, so cloud-first stacks quickly become too heavy to run where the data starts.
Networks are intermittent, flaky, and often expensive to depend on for every message, every time.
Bandwidth is expensive, data is high-volume but low signal, and teams are forced to push cloud-first architectures into environments where they do not fit.
An Apache Kafka compatible event broker built for high-velocity data over flaky networks and constrained devices.
Integrate without changing your existing ecosystem.
Leafcuttr sits at the edge, where buffering, aggregation, and forwarding can happen efficiently even when conditions are unreliable.
Keep data local, shape it intelligently, and forward only what matters upstream.
Leafcuttr delivers Kafka compatibility, multi-protocol ingestion, resilience, schema registry, observability, and async replication for edge teams.
Fully compatible with the Kafka protocol so teams can integrate without reworking their existing ecosystem.
Native support for MQTT, HTTP, and Kafka, with no need for proxies or additional layers.
Runs on constrained devices with low CPU and memory usage.
Handles flaky networks and intermittent connectivity without collapsing the local pipeline.
No external service required to keep schemas aligned as message formats evolve.
Metrics and monitoring are part of the product, not something you bolt on later.
Async replication keeps data moving upstream when connectivity is available, without blocking local streaming.
Workflow
Leafcuttr keeps data close to the source, survives bad networks, and forwards only the signals that matter upstream.
Leafcuttr runs on edge devices or gateways close to where data is generated.
It accepts MQTT, HTTP, and Kafka traffic from devices and local applications.
When networks fail, Leafcuttr keeps buffering locally instead of dropping the flow.
Data can be shaped at the edge so downstream systems receive less noise and more signal.
Leafcuttr forwards to central cloud systems when connectivity returns and capacity allows.
There is no constant connectivity requirement and no large distributed cluster to keep alive at the edge.
Where it fits
Leafcuttr fits the places where cloud-first stacks break down: low bandwidth, intermittent networks, and devices that need to keep running even when the connection does not.
Industrial
Process machine data locally with minimal latency, even in plants with unreliable connectivity and constrained hardware.
Buildings
Handle distributed sensor data efficiently across floors, sites, and building systems.
Retail
Keep stores in sync with dependable local buffering and remote delivery when connectivity returns.
Video
Manage high-volume streams at the edge without forcing every byte upstream.
Mobility
Stream data through unstable networks while vehicles are in motion and routes are changing.
Robotics
Enable real-time decisions without depending on a cloud round trip for every event.
We’re collaborating with early adopters to refine Leafcuttr for real-world use cases.